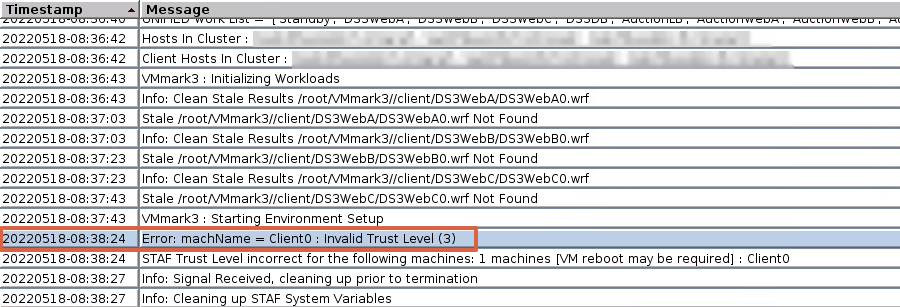
Dernièrement nous avons testé VMmark 3.1.1 (pour rappel VMmark permet de bencher et mesurer l‘évolution des plates-formes virtuelles) afin de bencher des serveurs DELL (PowerEdge R7515). On vous passe les étapes douloureuses (nous ferons un billet sur l’installation de VMmark 3.1.1 très prochainement) de l’installation et la configuration. Une fois l’installation terminée on lance notre premier Tile et là une belle erreur (ce n’est pas comme si c’était la première en plus…) mais celle-là aurait pu être évitée (genre RTFM) : “Error : machine = client0: Invalid Trust Level (3).
Ca commence pas bien notre affaire 🙂
La seule info qui nous intéresse dans le message d’erreur est “Client0”, comme tout bon Sysadmin on fait un ping de notre fameux “Client0”, comme nous n’avons pas de retour, direction le vCenter.
Sans IP elle ne risque pas de répondre notre CLIENT0 🙂
En allant plus loin on constate que l’IP du CLIENT0 (192.168.1.2) a été attribué à la VM DeployVM0 (le conflit d’IP explique notre message d’erreur). Direction le fichier VMmark3.properties (situé dans /root/VMmark3 de la VM “PrimeClient”) afin de voir si on n’a pas un problème de configuration sur la VM “Client0” ou DeployVM0. Après une recherche dans le fichier VMmark3.properties on comprend d’où vient le problème, le deploy/DeployVMinfo est égal à DeployVM0:192.168.2 soit l’IP de de notre VM “CLIENT0”.
Il ne reste plus qu’à mettre la bonne IP
Quand on lit le commentaire “Specifies the name and IP address of the deployed VMs. Ex DeployVM0:192.168.1.245,DeployVM1:192.168.1.246” on se dit qu’on a raté quelques chose 🙂 .
Une fois l’IP de la VM “DeployVM0” passer sur 192.168.1.245 notre Tile est passé sans encombre
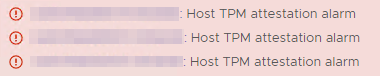
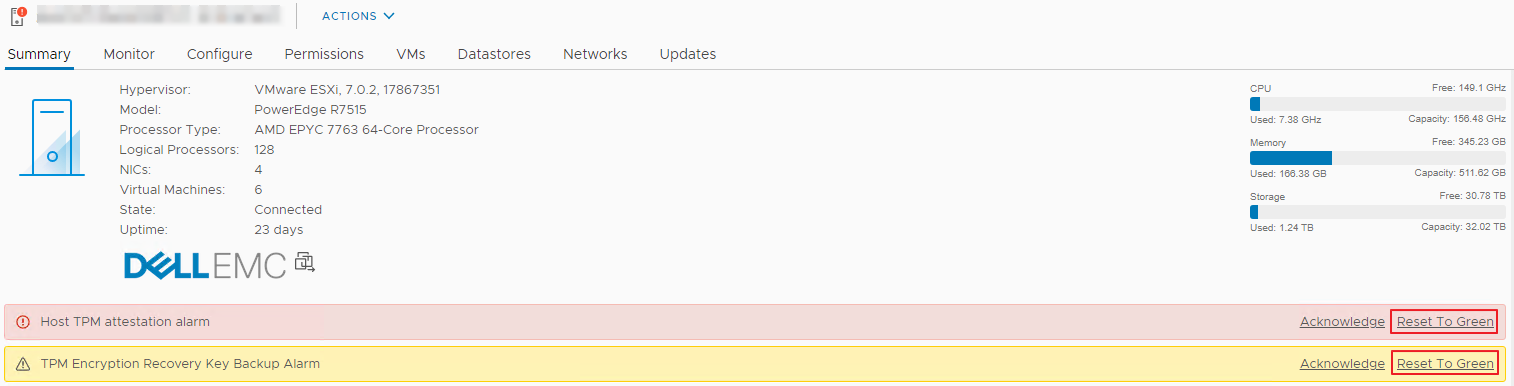
Sur plusieurs hosts PowerEdge R7515 nous avons constaté après l’installation d’ESXi 7.0.2 (17867351) une erreur TPM sur un de nos vCenter de test (notre fameux POC VCF) :
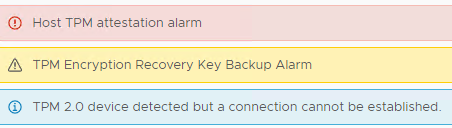
Host TPM attestation alarm
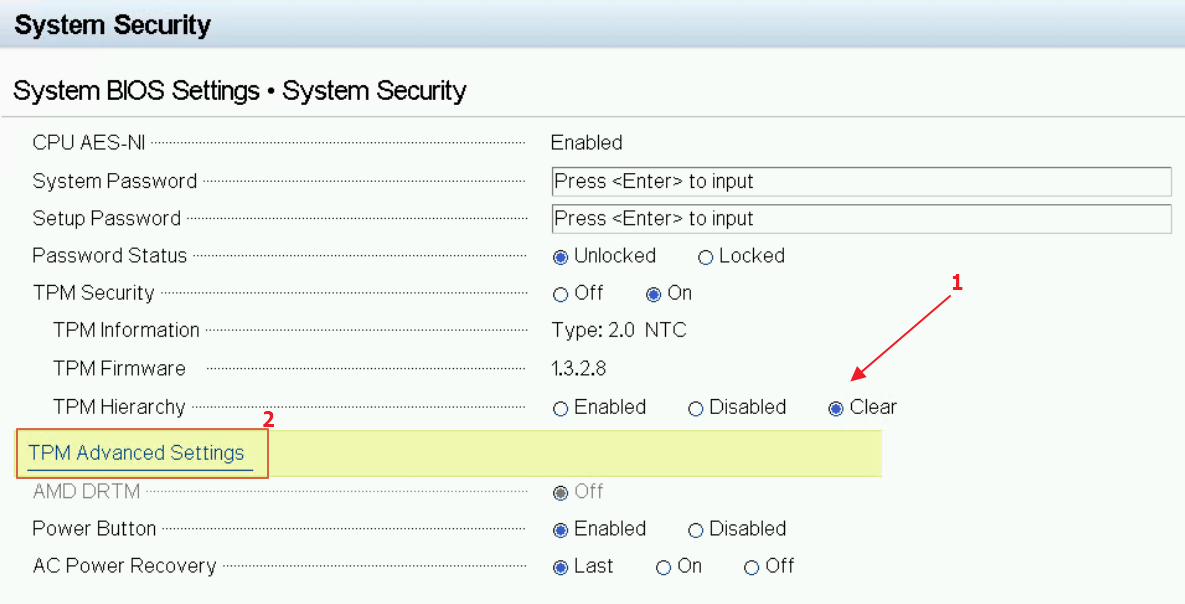
L’erreur se produisant uniquement sur des PowerEdge R7515 il semblerait que nous ayons oublié de paramétrer correctement la partie TPM dans la config de nos serveurs DELL 🙂 . Direction l’ IDRAC pour vérifier ça.
Aller dans le BIOS (F2)
BIOS Settings-System Security
Dans un premier temps on fait un clear avant de paramétrer la suite
Cliquer sur Clear (confirmer en cliquant sur le bouton Ok lors de l’affichage du popup).
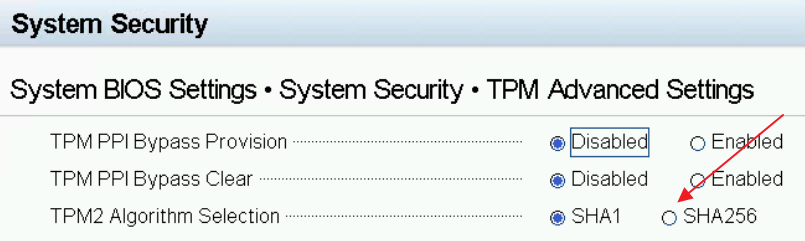
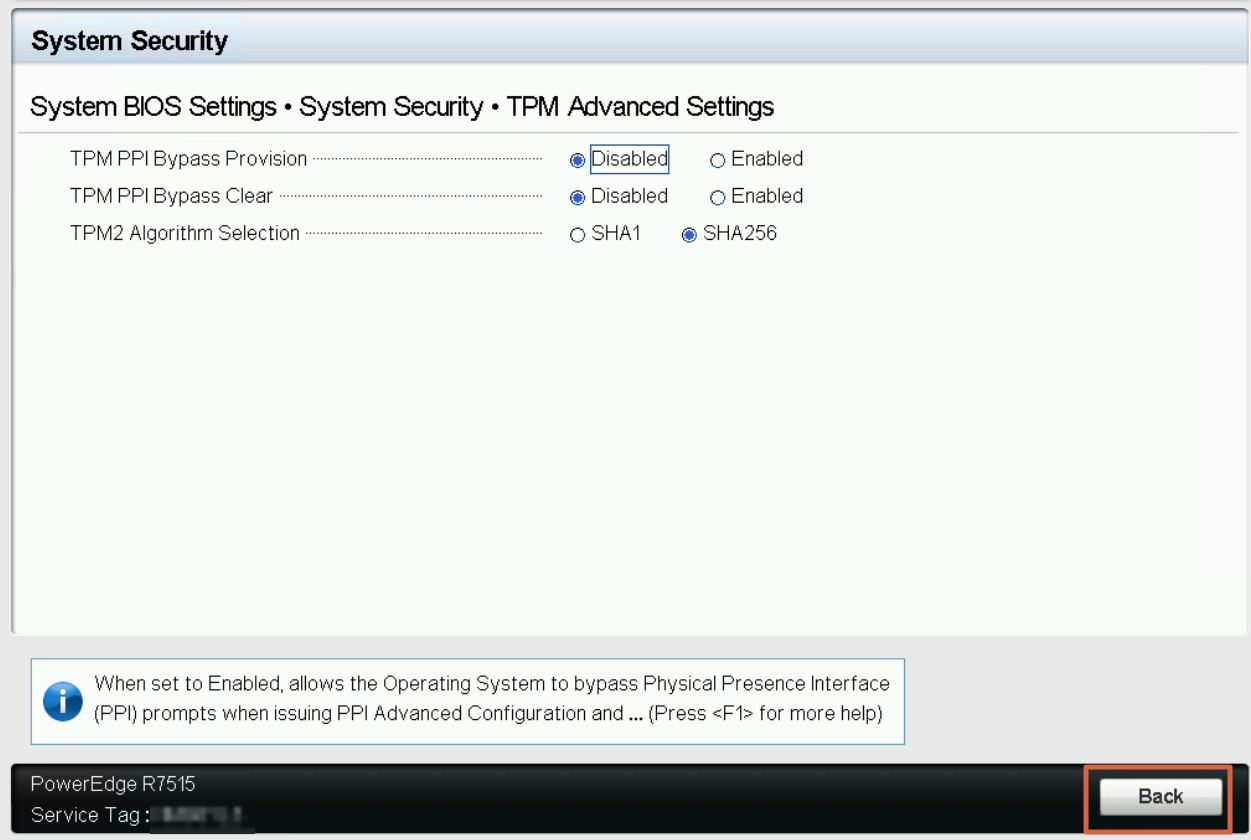
Cliquer sur TPM Advanced Setting.
Cliquez sur SHA256 (voilà pourquoi on avait l’erreur)
Cliquez sur le bouton Yes
Cliquez sur bouton Ok
Cliquez sur le bouton Back
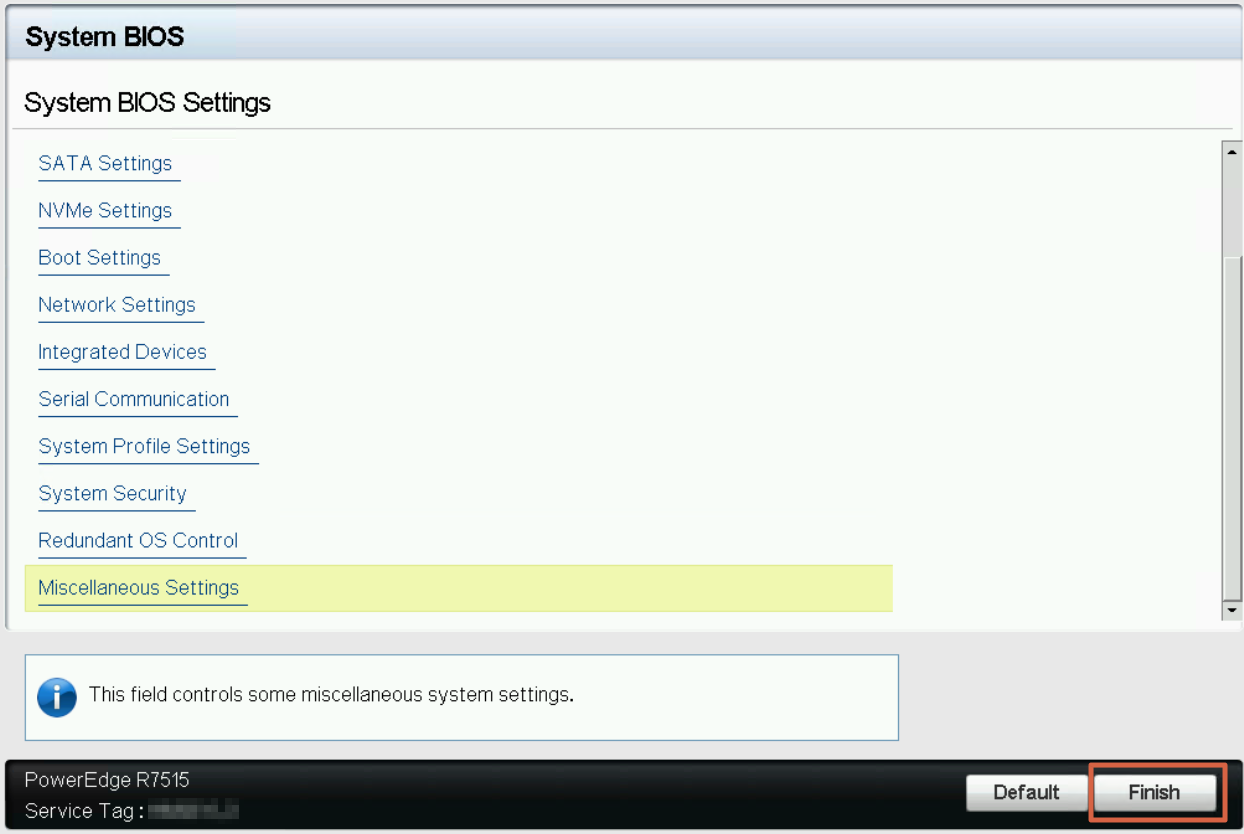
Cliquez sur le bouton Finish
Cliquer sur le bouton Finish
Cliquez sur le bouton Yes
Cliquer sur Reset To Green (et dans notre cas on pourra relancer l’upgrade de ce Workload Domain dans VCF 🙂 )
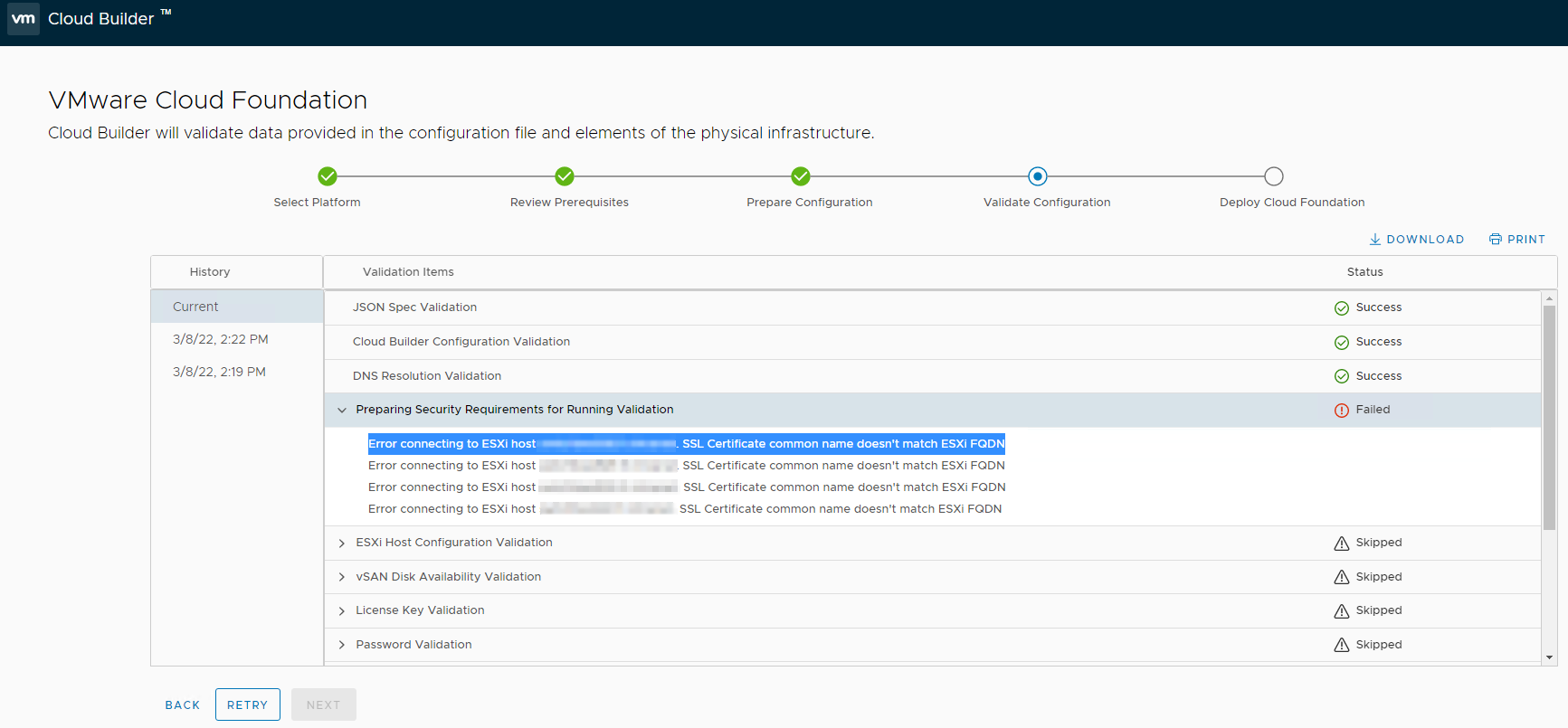
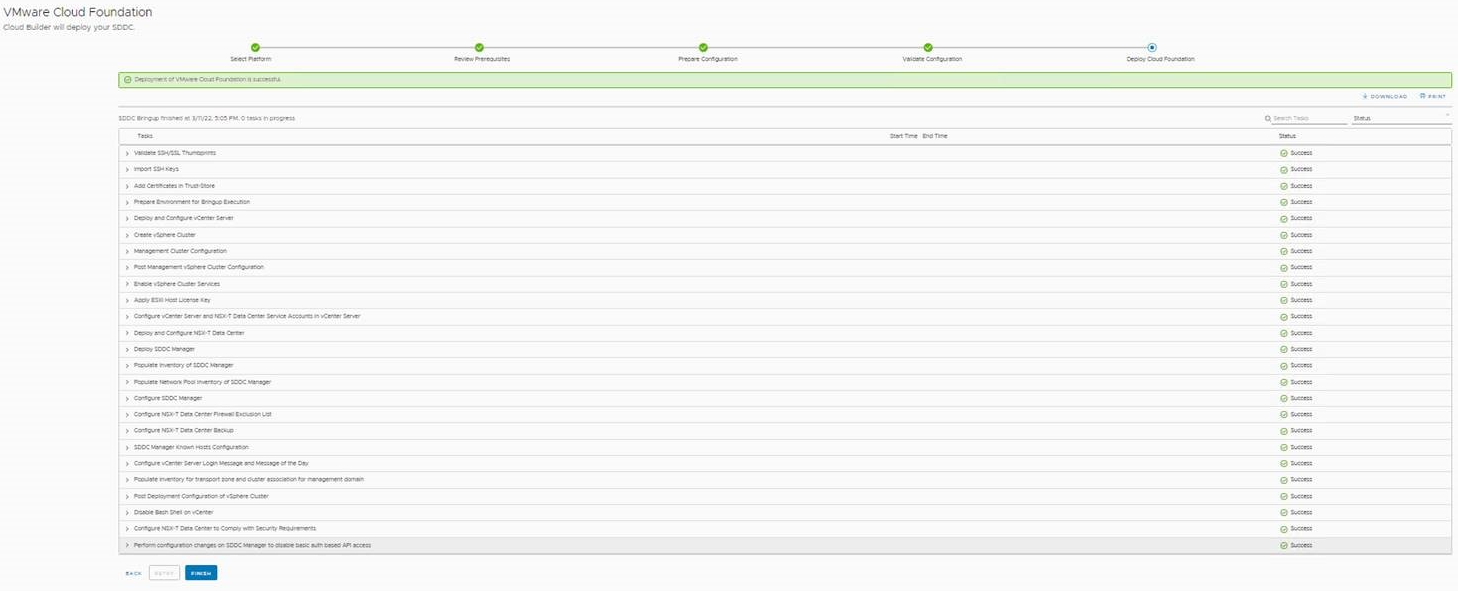
Dans le cadre d’un POC VCF 4.3.0 (VMware Cloud Foundation) nous avons rencontré une erreur (ou plutôt nous avons retenu celle-là 🙂 ) lors de l’installation du Cloud Builder. Lors de l’étape “Validate Configuration” tout se passait bien jusqu’à l’apparition d’un Failed associé à l’erreur “Error connecting to ESXi host xxxx. SSL certificate common name doesn’t match ESXi FQDN” sur les quatre host de notre POC.
C’est sur que si le Cloud Builder ne peut pas se connecter aux ESXi ça va être dur pour la suite 🙂
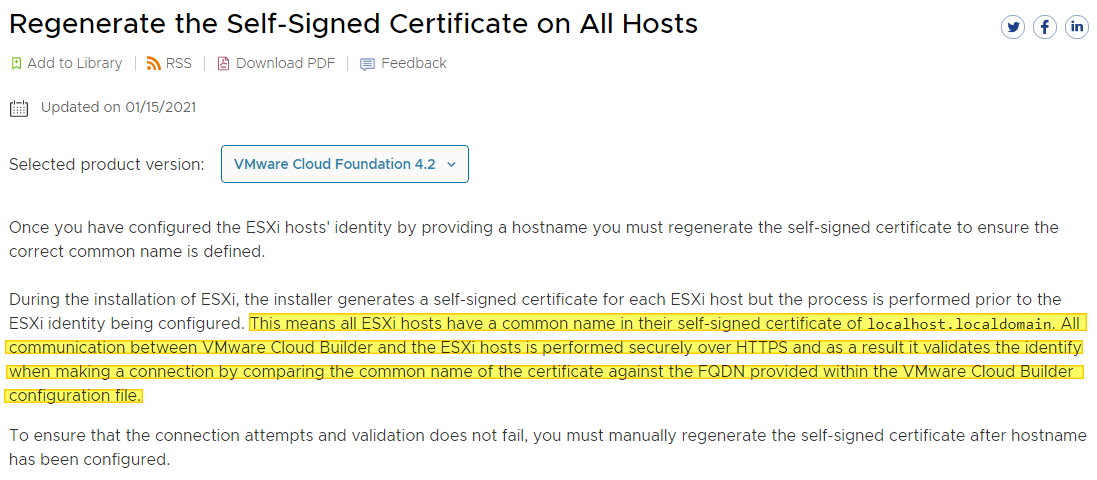
Le message d’erreur “Error connecting to ESXi host xxxx. SSL certificate common name doesn’t match ESXi FQDN” est explicite, le certificat par défaut des ESXi ne convient pas au Cloud Builder pour se connecter aux ESXi, du coup impossible pour Cloud Builder d’aller plus loin. En relisant les pré-requis on s’aperçoit que depuis la version 4.2 de VCF, il faut que le certificat de l’ESXi soit au format host.FQDN (et corresponde bien sûr à ce qui est rentré dans votre fichier de configuration Cloud Builder).
Comme indiqué par VMware les étapes pour régénérer le certificat sont très simples :
Connectez-vous en SSH sur chaque hôte ESXi.
Lancez la commande “esxcli system hostname get” et vérifiez que Host est bien au format Host.FQDN dans la section “Fully Qualified Domain Name: “, si c’est bien le cas passez directement à l’étape 6.
Lancez la commande “vi etc/hosts” puis ajouter votre Host.FQDN et enregistrer (touche “echap” puis “:wq!”.
Lancez la commande “esxcfg-advcfg -s Host_FQDN /Misc/hostname” (remplacer Host_FQDN par le nom de votre host et son FQDN).
Lancez la commande “reboot”
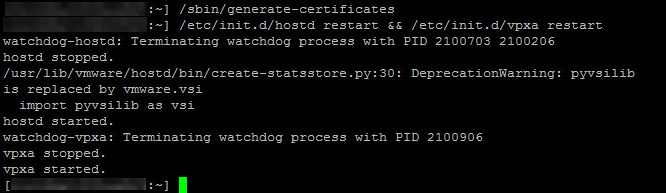
Lancez la commande “/sbin/generate-certificates“puis validez
Lancez la commande “/etc/init.d/hostd restart && /etc/init.d/vpxa restart“
Il ne vous reste qu’à faire un “retry” dans le Cloud Builder 😉 .
Et voilà 🙂 la suite dans un prochain billet (on vous promet c’est fun)
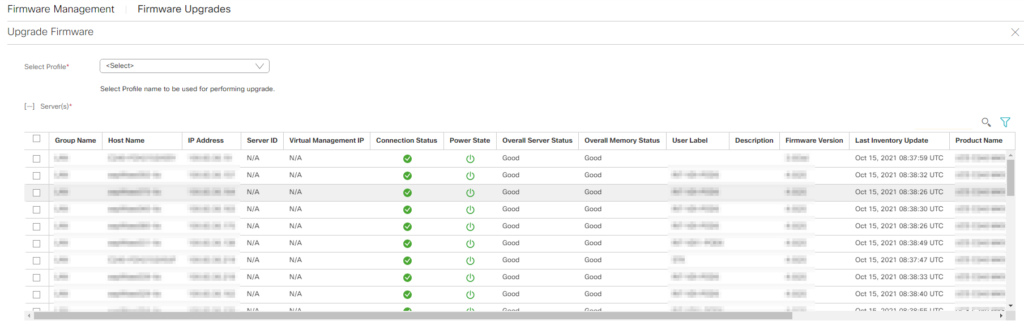
Déployer un firmware via IMC Surpervisor est très simple encore faut-il que cela fonctionne, et c’est toujours quand on n’a pas le temps que cela se complique 🙂 . Sur Une IMC Supervisor (ver : 2.2.0.0) nous devions déployer un firmware sur un Serveur Cisco M5, mais le menu “Firmware Upgrade” en avait décidé autrement. En effet lorsque l’onglet “Firmware Upgrade” s’affichait, la liste des serveurs (tout du moins le bouton +) ne s’affichait pas, seule une barre de progression qui tournait sans fin nous tenait compagnie.
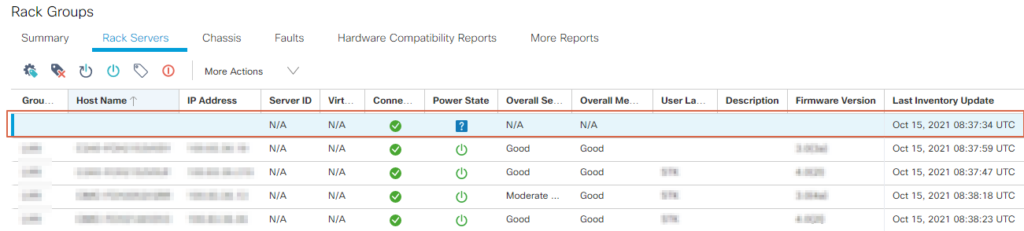
Sur la page Rack Groups, onglet “Rack Servers” on remarque une ligne avec des éléments manquants (seule le Last Inventory Update) apparaît.
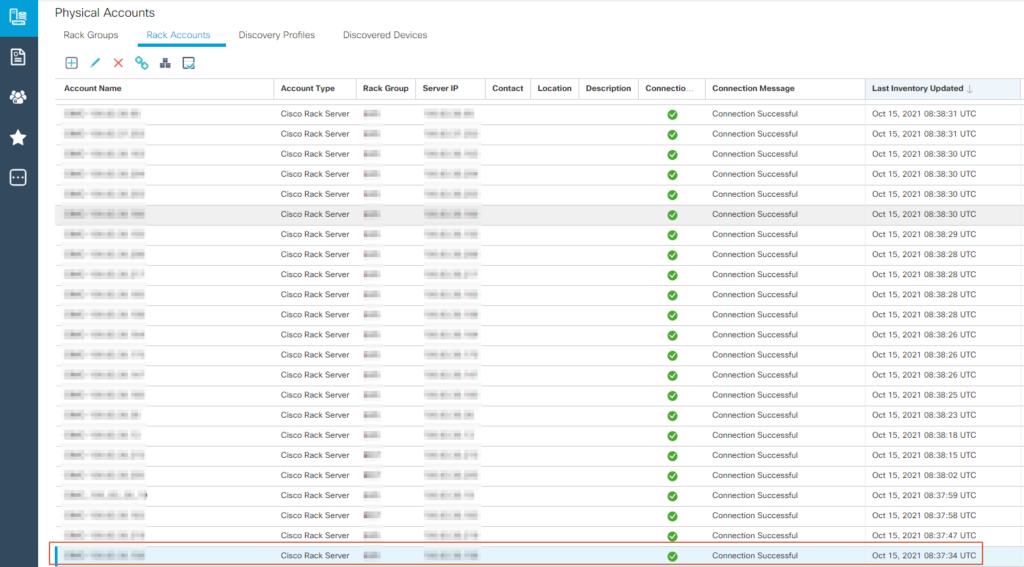
Avec l’information “Last Inventory Update” nous allons regarder dans la page Physical Account (onglet “Racks Accounts”) si nous trouvons quelque chose.
Bingo on retrouve notre serveur, cette fois avec toutes ses informations
Nous avons supprimé ce serveur afin de vérifier que c’était bien la cause de notre problème (dans le menu “Firmware Upgrade”), puis nous sommes allés tester le menu “Firmware Upgrade”.
Nickel ça passe (il ne reste plus qu’à rajouter notre serveur supprimé)
Récemment sur un vRLI4.8.0-13036238, nous avons constaté que le compte par défaut de Cassandra (user : cassandra) avait un mot de passe qui ne respectait pas les critères de sécurité de notre entreprise. Pour faire un reset du mot de passe du compte user “cassandra” dans Cassandra (vous nous suivez ? 🙂 ) , il faut ouvrir une console SSH sur votre vRLI puis entrer dans Cassandra et lancer deux commandes.
Une fois connecté en SSH sur votre vRLI, lancer la commande ci-dessous afin de rentrer dans Cassandra.
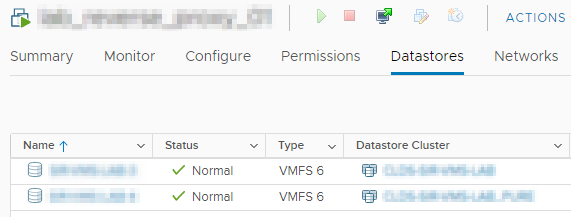
Lors d’un dernier check de routine avant une decomm de Datastore nous avons eu l’agréable surprise de tomber sur une VM qui avait deux Datastores qui eux-mêmes appartenaient à deux clusters de Datastore différents (jusqu’a là pourquoi pas… mais vu que la dite VM n’avait rien à faire là, nous avons voulu en savoir plus.)
Là où c’est rigolo c’est que le premier Datastore est complètement vide et que le deuxième Datastore contient bien tous les fichiers de notre VM 🙂
On s’aperçoit aussi que toute modification de la VM est impossible (ce qui nous étonne qu’à moitié) et que notre VM a une ISO attachée (ça donne une bonne piste vous l’aurez compris.)
En googlelant nous sommes tombés sur la KB2105343 qui explique en détail comment procéder pour supprimer le Datastore “intrus”.
Vérifier l’emplacement du fichier vmx de la vm
Faire un “Power Off” de la vm
Faire un “Remove from Inventory” de la vm
Inventorier la vm dans le vCenter
Faire un clique droit sur la vm, Edit Setting, dans “CD/DVD drive 1*” choisir “Client Drive” puis cliquer sur le bouton “OK”
Vous pouvez “Power On” la VM si vous le souhaitez
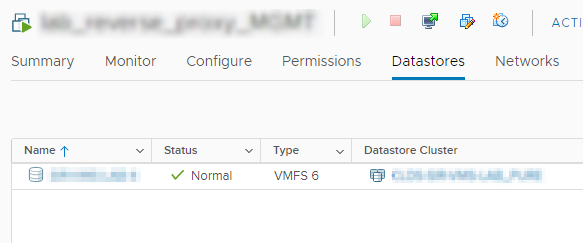
Nous avons désormais un seul Datastore et on va pouvoir décommissionner notre Datastore vide 🙂
Lors d’un Storage vMotion en masse nous avons rencontré sur certaines VMs l’erreur ci-dessous.
A specified parameter was not correct: ConfigSpec.files.vmPathName
En regardant de plus près même la suppression d’une des VMs en question n’était pas possible non plus (au préalable on a bien vérifié qu’on avait un backup récent 🙂 ).
Afin de pouvoir terminer notre Storage vMotion nous avons dû faire un “Remove from Inventory”sur les VMs qui posaient problème puis les inventorier dans le vCenter (6.7.0.48000)
Ci-dessous la commande pour afficher les VMs d’un vCenter avec leurs clusters, dossiers et le chemin du vmx.
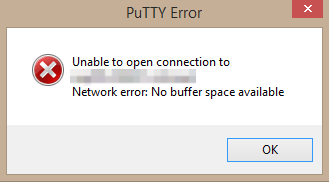
Avec un titre comme ça il faut qu’on vous plante le décor au préalable ; nous avons un cluster de deux hosts dont un est en maintenance, les deux serveurs d’admin (RDSH) qui sont hébergés sur l’autre host commence à être chargés, sur un de nos serveur d’administration nous avions déjà une session en mode déconnecté depuis une vingtaine heures environ. La reconnection à notre session s’est faite sans problème (une chance car l’autre serveur refuse toute connexion) cependant lorsque nous avons essayé de lancer une connection distante (SSH) via PuTTY nous avons rencontré l’erreur ci-dessous :
Network error : No buffer space available
Notre premier bug PuTTY 🙂
Dans le journal system nous avons trouvé l’Event ID 4227 qui visiblement a un lien direct avec notre problème.
TCP/IP failed to establish an outgoing connection because the selected local endpoint was recently used to connect to the same remote endpoint. This error typically occurs when outgoing connections are opened and closed at a high rate, causing all available local ports to be used and forcing TCP/IP to reuse a local port for an outgoing connection. To minimize the risk of data corruption, the TCP/IP standard requires a minimum time period to elapse between successive connections from a given local endpoint to a given remote endpoint.
Outre le problème rencontré avec PuTTY, nous ne pouvons plus “sortir” du serveur, que ce soit via l’accès à un partage distant, un telnet, un rdp, AD etc.. etc….. . Un google plus loin nous comprenons qu’il se pourrait que notre serveur ait un problème de port dynamique (AKA “Ephemeral Port“). Afin d’afficher la liste et l’état des connexions (ce qui nous intéresses ce sont les connexions en TIME_WAIT) sur notre serveur nous avons utilisé la cmdlet “Get-NetTCPConnection” comme ci-dessous :
Get-NetTCPConnection -state timewait
Nous avons constaté un nombre conséquent (environ 200) de connexions en TIME_WAIT (malheureusement nous n’avons pas eu le temps de faire un screenshot, juste le temps de noter les PID coupables, et comme c’est de la prod on ne kill pas les PID sans savoir), on comprend mieux pourquoi PuTTY ne trouve pas un port dynamique de libre. Afin de connaître la plage des ports dynamiques il faut lancer la commande ci-dessous :
netsh int ipv4 show dynamicport tcp
Notre server a une une plage par défaut pour un Windows 2019
La solution de facilité serait de rebooter le serveur (mais nous avons toujours des utilisateurs connectés sur le serveur), nous optons pour agrandir la plage des ports dynamiques (sans redémarrer le serveur) . Afin d’agrandir la plage des ports dynamiques et réduire le temps de libération d’un port qui passe en TIME_WAIT de quatre minutes (valeur par défaut) à 30 secondes nous avons passé les clés de registre ci-dessous (qu’on expliquera plus bas) via une console PowerShell.
Nous relançons un “netsh int ipv4 show dynamicport tcp” afin de vérifier que la plage des ports dynamique a bien été agrandie.
Notre plage est désormais agrandie
On teste si PuTTY se lance bien avec la plage des ports dynamiques agrandie.
Nickel (ça passe sans reboot)
Quelques explications sur les trois clés passées plus haut.
MaxUserPort : Permet de fixer la plage des ports dynamiques, par défaut la plage sur Windows 2019 commence à 49152 et se termine à 65535
TcpTimedWaitDelay : détermine la durée pendant laquelle une connexion TCP reste dans l’état TIME_WAIT (ou 2MSL) lorsqu’elle est fermée. La valeur par défaut d’un TIME_WAIT est de 240 secondes (4 mn) soit 120 secondes pour MSL qu’on double pour avoir deux MSL (2MSL).
TcpNumConnections : nombre de connexions TCP ouvertes simultanées
Un peu de littérature autour des ports dynamiques :
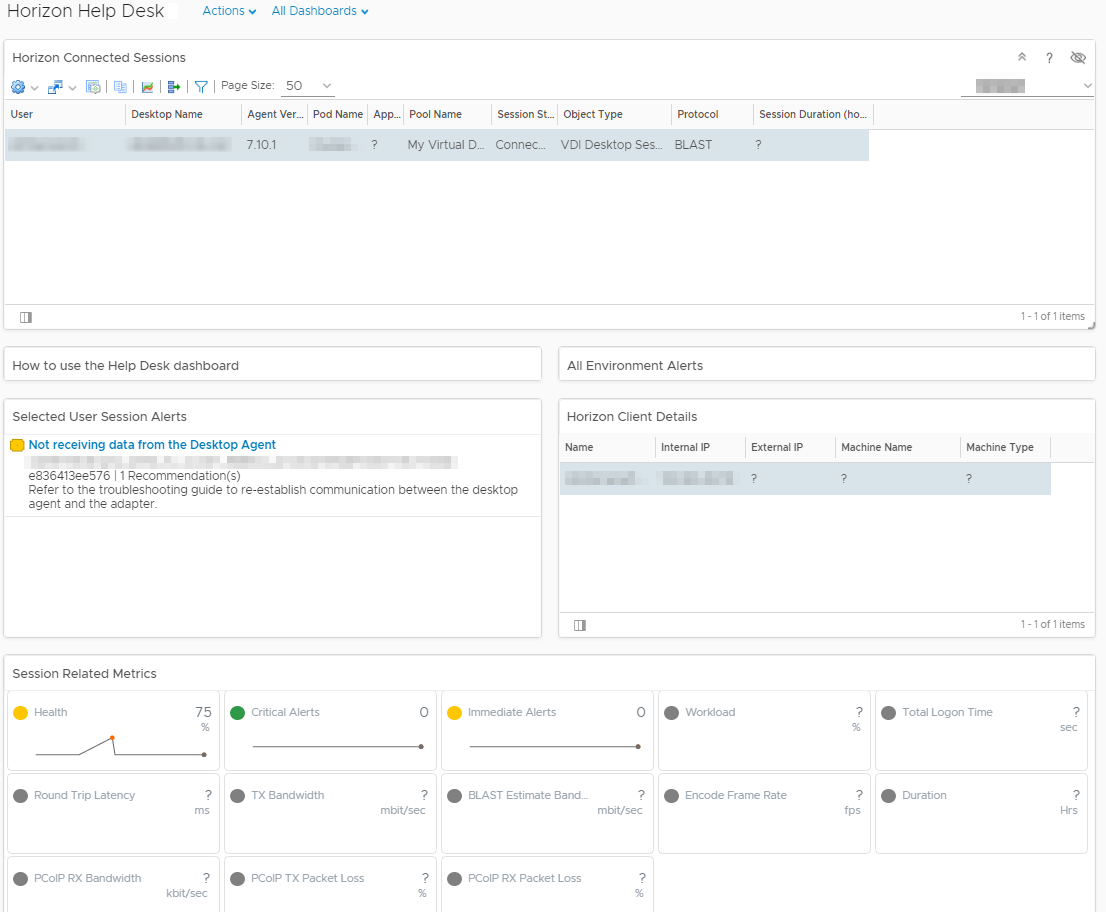
Nous voilà de retour avec vROps (vous allez croire qu’on est fan à force), cette fois-ci ce sont des vms de type dekstop qui ne remontaient plus d’infos dans vROps depuis leur Desktop Agent. Le message d’erreur dans le dashboard “Horizon Help Desk” était :
Not receiving data from the Desktop Agent
Ne soyons pas médisants on a déjà le protocole qui remonte 🙂
En collaboration avec notre collègue de l’équipe “Poste de Travail” (Christophe Mazzardis) nous avons regardé sur plusieurs vms impactées et avons remarqué que dans la log de l’agent View (C:\ProgramData\VMware\vRealize Operations for Horizon\Desktop Agent\logs\v4v-vrops-rmi-YYYY-MM-DD.log) nous avions l’erreur ci-dessous :
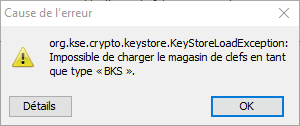
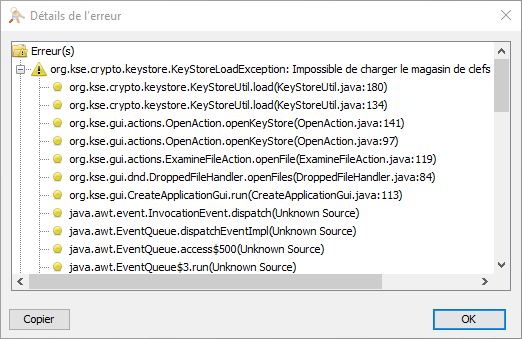
0x00002e70 ERROR Failed to initialize RMI in the Java client. java.io.IOException: Invalid keystore format
Vous l’aurez compris le “Invalid keystore format” nous a permis rapidement de faire la liaison avec le fichier “v4pa-truststore.jks” (ce fichier contient le magasin de confiance que l’adaptateur utilise pour authentifier le certificat du broker agent) situé dans “C:\ProgramData\VMware\vRealize Operations for Horizon\Desktop Agent\conf”. En remplaçant le fichier “v4pa-truststore.jks” par un fichier d’une vm ne posant pas de problème et en relançant le service “v4v_agent” (Vmware vRealize Operations for Horizon Desktop Agent) nous avons pu à nouveau obtenir la remontée des métriques view dans vROps.
On regarde vite fait dans le fichier de log Agent\logs\v4v-vrops-rmi-YYYY-MM-DD.log pour voir si ça se passe bien.
7:14:46 0x00000a68 INFO Using message server ‘rmi://vROPsIP:3091′. 17:14:46 0x00000a68 INFO UnregisterDataDumpCallback success: (, , ) 17:14:46 0x00000a68 INFO RegisterDataDumpCallback success: (rmi:// vROPsIP:3091, 539dc7df8b99f2fbddfe841c9332b8dabe1426eee73b449c3b3bfd7fc3d4c1ba, 0500304531153013060355040A130C564D776172652C20496E632E312C302A060355040313237643656E746572204F7065723656E746572204F706573656E746572204F706573656E7B83E986FD33AC301EE104FC25C1DE7435495A………………) 17:14:46 0x00000a68 INFO Using message server ‘rmi:// vROPsIP:3091’. 17:14:46 0x00000c0c INFO Using JRE from ‘C:\Program Files\VMware\VMware View\Agent\jre\’. 17:14:47 0x00000c0c INFO SUCCESSFULLY initialized the Message Logger. 17:14:47 0x00000c0c INFO Initialized communication manager. 17:14:47 0x00000c0c INFO Updated the message server URL in the Java client to rmi:// vROPsIP:3091.
Le “SUCCESSFULLY initialized the Message Logger” confirme que tout est ok.
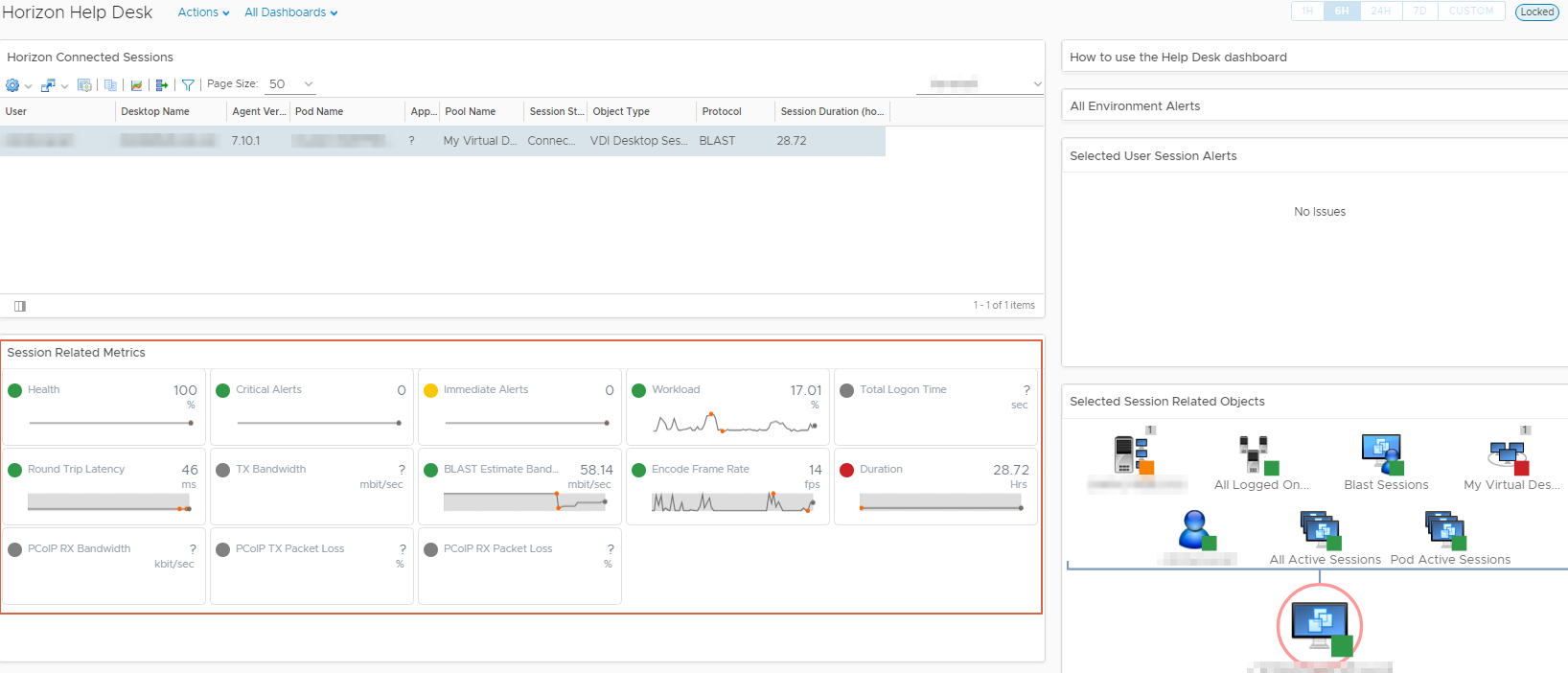
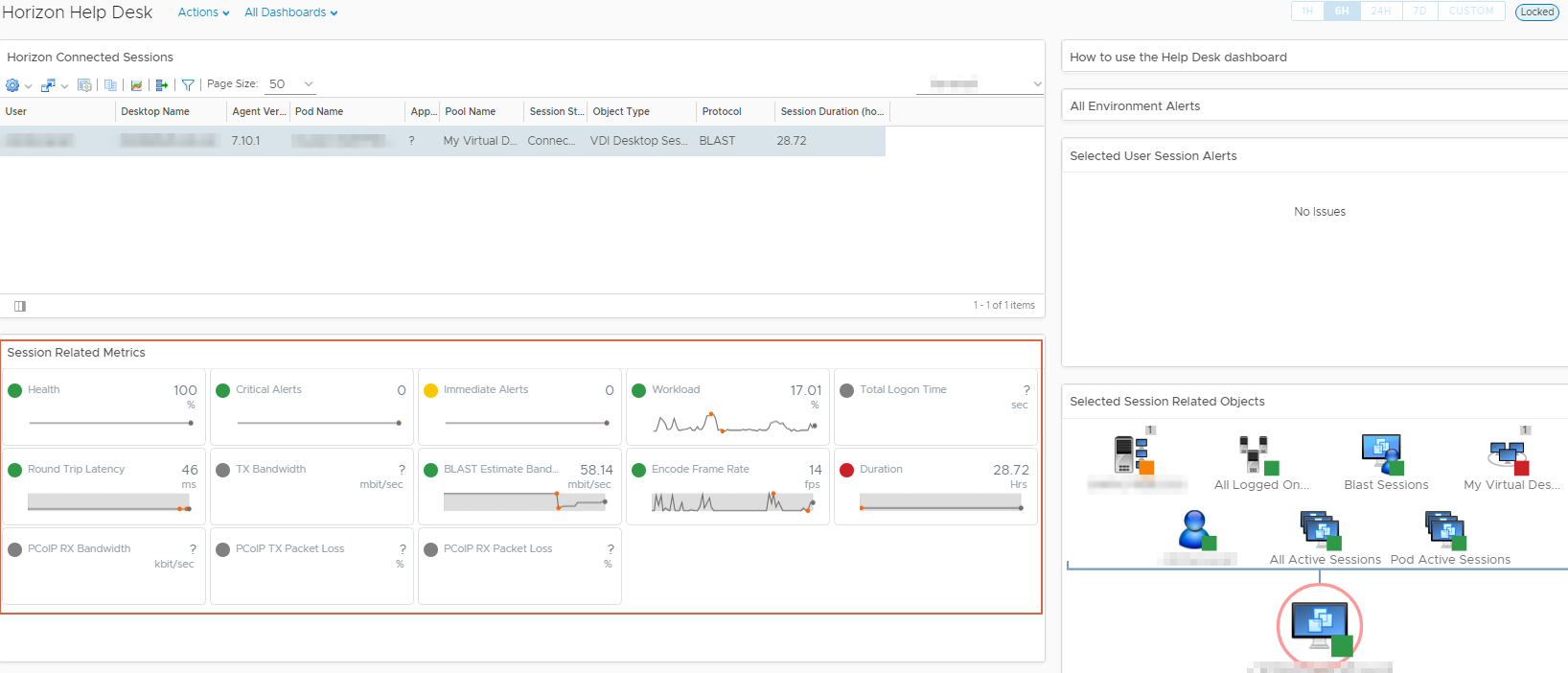
Retournons côté vROps afin de voir si notre vm a bien ses métriques View qui remontent.
Après quelques minutes tout est ok
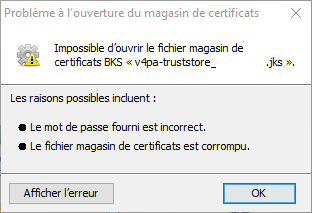
Maintenant que le problème est résolu, on va essayer de lire le fichier “v4pa-truststore.jks” (qui causait problème) via “KeyStore Explorer” (le mot de passe du fichier “v4pa-truststore.jks” est contenu dans le fichier “msgclient.properties” (truspass =……..).
Comme nous sommes sur du mot de passe, nous optons pour “le fichier magasin de certificats est corrompu”….on va cliquer sur Ok comme on est joueur
Et en cliquant sur le bouton Détails ?
Nous ne sommes pas plus avancés pour l’instant…..
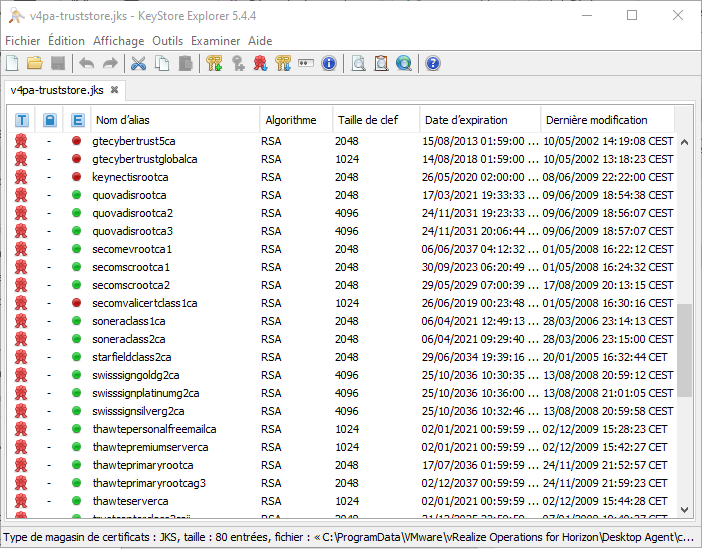
Maintenant nous allons regarder ce qu’il y a dans un fichier “v4pa-truststore.jks” sain.
On a bien la liste des certificats 🙂
Retournons côté vROps pour voir si notre vm remonte bien les métriques View.
Dans un vROps (8.01) dédié à une infra Horizon View (ver 7.10) nous sommes tombés sur un “No Data” dans le Dashboard “Horizon Adapter Self Health” dans la section “Horizon Broker Agent Event DB Collection Statistics”.
On sent qu’on va adorer la suite… 🙂
Direction le Connection Server où est installé le Broker Agent afin de vérifier que tout est bien configuré (pour la partie Event DB). Allez dans le menu Démarrer – Executer et tapez la commande ci-dessous afin de lancer le “Broker Agent Config Utility for Horizon”.
C:\Program Files\VMware\vRealize Operations for Horizon\Broker Agent\bin\v4v_brokeragentcfg.exe
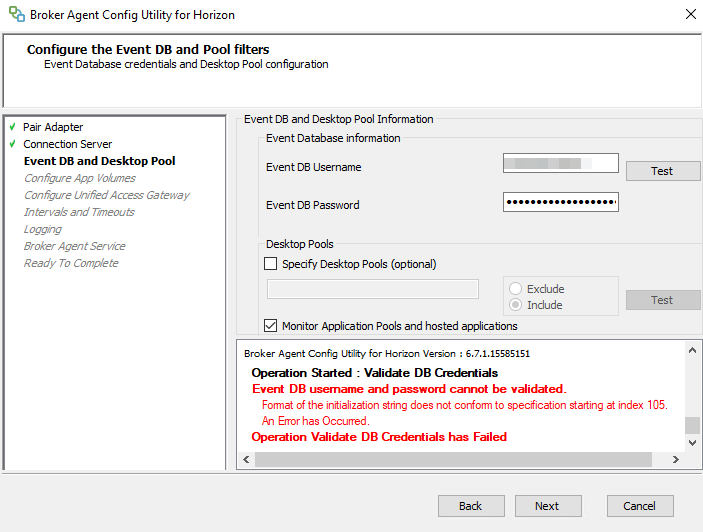
Passez les étapes de Pairing et de Connection Server, nous arrivons à l’écran “Configure the Envent DB and Pool Filters”, lors du test username/password nous obtenons l’erreur ci-dessous :
Event DB username and password cannot be validated Format of the initialization string does not confirm to specification starting at index 104 An error has Occurred Operation Validate DB Credential has Failed
On commence à comprendre notre “No data” dans vROPs”
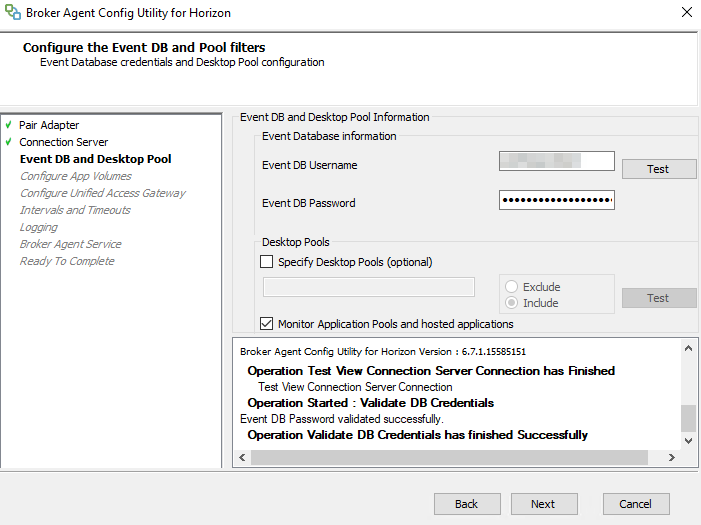
Là ou ça devient intéressant c’est que le username/password utilisé est déjà utilisé dans la console View (dans la partie Configuration d’événements). Côté SQL les logs ne font même pas apparaître un problème d’authentification. Vu que l’association username/password fonctionne via la console view et ne fonctionne pas via l’agent broker, nous avons testé avec un mot de passe moins complexe.
Avec un password sans certains caractères spécifiques ça passe sans problème 🙂
Reste à voir dans le vROps ce que ça donne pour notre problème de “no data” dans le Dashboard “Horizon Adapter Self Health” dans la section “Horizon Broker Agent Event DB Collection Statistics”